
Na Tenchi, tomamos uma decisão ponderada e deliberada quando escolhemos inicialmente o stack de tecnologia para nosso produto, o Zanshin. Em 2019, quando começamos, tínhamos apenas uma ideia inicial do que nosso produto seria. Não era possível prever seu enorme sucesso, como o mercado evoluiria e o que os clientes exigiriam do produto. No entanto, começamos com a seguinte base em mente:
- Simplicidade e sem complicações. Sabíamos que não queríamos gastar um épsilon de tempo configurando e ajustando servidores padrão ou VMs.
- Escalabilidade. Ninguém cria uma startup pensando que o produto não venderá. Mas ainda assim, muitas startups caem na armadilha de que podemos “comprar mais capacidade mais tarde”. Isso só é verdade se você projetar seu sistema para escalabilidade. Planejamos isso desde o início.
- Ignoramos lock-in com provedor de nuvem. Isso pode parecer contraintuitivo. Não estar vinculado a um único provedor de nuvem, como GCP, Azure ou AWS, é geralmente uma coisa boa. No entanto, quase todo mundo sabe que isso é muito mais difícil e demorado de alcançar do que parece à primeira vista. E investir esforços na construção de ferramentas e infraestrutura agnósticas em nuvem é um erro para quase qualquer startup e certamente não é algo para se preocupar nos primeiros estágios.
- Segurança por design. Como empresa de segurança, é nossa obrigação ser ainda mais segura do que as empresas mais seguras do mercado.
Com esses princípios em mente, escolhemos nossa stack de tecnologia. E agora, quatro anos depois, é hora de olhar para trás e decidir se essa stack de tecnologia foi a escolha correta e, se não, o que poderia ter sido melhor e como planejamos seguir em frente.
A principal decisão que tomamos foi usar uma arquitetura sem gerenciar servidor e, especificamente, o Serverless Framework, usando AWS. Isso nos trouxe os três primeiros pontos acima quase que instantaneamente. O quarto, a segurança, certamente foi simplificado do que se tivéssemos escolhido construir nossa stack de tecnologia em arquiteturas de servidor virtual mais tradicionais.
Ao contrário da arquitetura de servidor tradicional, onde os desenvolvedores devem gerenciar e provisionar servidores, uma arquitetura sem servidor transfere essa responsabilidade para o provedor de nuvem. Essa mudança de foco permite que os desenvolvedores se concentrem em escrever código e construir a lógica de aplicativos sem se preocupar com tarefas de gerenciamento de infraestrutura.
Para recapitular, aqui está o que uma arquitetura sem servidor oferece em termos de prós e contras.
Prós das arquiteturas sem servidor:
- Custo-benefício: A arquitetura sem servidor oferece um modelo de pagamento por uso, o que significa que só se paga pelos recursos consumidos. Isso elimina a necessidade de investir em custos de hardware antecipados ou pagar por capacidade de servidor sobressalente, levando a economias de custo significativas e facilitando o planejamento de capacidade.
- Escalabilidade: Os aplicativos sem servidor escalam automaticamente com base na demanda. Conforme o tráfego aumenta, o provedor de nuvem aloca dinamicamente recursos adicionais para lidar com o aumento, garantindo desempenho e disponibilidade ininterruptos.
- Facilidade de desenvolvimento: As equipes de engenharia podem se concentrar em escrever código e lógica de negócios sem se envolver no provisionamento e manutenção de servidores. Essa abordagem simplificada acelera os ciclos de desenvolvimento e aumenta a produtividade.
- Alta disponibilidade: A arquitetura sem servidor é inerentemente resiliente devido à sua natureza distribuída. Se uma instância de servidor específica falhar, outras instâncias assumirão o controle perfeitamente, garantindo uma operação ininterrupta do aplicativo. Além disso, é trivial aproveitar várias zonas de disponibilidade da AWS para que seu aplicativo possa até sobreviver a falhas inteiras do data center com facilidade.
- Segurança: Em segurança, uma tarefa fundamental é manter os servidores e a infraestrutura de rede adequadamente dimensionados, atualizados e corrigidos (com patches e updates) para os mais novos padrões de segurança. Ao transferir essas tarefas básicas para o provedor de nuvem e aproveitar ao máximo o modelo de responsabilidade compartilhada, evitamos desperdiçar esforços de engenharia em atividades não diferenciadas, demoradas e propensas a erros, simplificando nossas vidas no processo.
Contras das arquiteturas sem servidor:
- Iniciações a frio ou “cold start”. Quando uma função sem servidor não foi executada recentemente, ela pode sofrer um atraso ou “iniciação a frio” enquanto o provedor de nuvem inicia um novo ambiente de execução. Isso pode afetar o desempenho de funções invocadas com pouca frequência. Existem maneiras de mitigar isso, por exemplo, reservando alguma capacidade para estar sempre disponível. Infelizmente, isso prejudica os benefícios de ter uma arquitetura verdadeiramente sem servidor (ou seja, pode-se acabar pagando por recursos ociosos).
- Imprevisibilidade de custos. Embora a arquitetura sem servidor ofereça economia de custos em geral, aplicativos com padrões de uso imprevisíveis podem incorrer em cobranças inesperadas. E esses aplicativos podem ser vítimas de ataques de negação de carteira (do inglês, Denial of Wallet), que acabam custando uma pequena fortuna. Isso é uma consequência do escalonamento automático que o sem servidor usa por padrão, e limites precisam ser projetados para garantir que os custos não fiquem fora de controle em um incidente. Tais limites não são necessariamente simples ou diretos.
- Complexidade de depuração. Solucionar problemas de aplicativos sem servidor pode ser mais complexo devido à natureza distribuída e dinâmica da infraestrutura subjacente. Existem maneiras de mitigar isso também. Em geral, isso não é tanto um problema do framework, mas um problema da criação de microsserviços e do uso de processamento assíncrono baseado em filas de tarefas.
Aqui está como a Tenchi lida com os contras:
Em relação a iniciações a frio: Configuramos nossos lambdas (as microfunções que atendem às nossas solicitações de API) para ter uma disponibilidade mínima fixa. Embora isso estabeleça um limite para o nosso custo, mantemos a disponibilidade instantânea e mantemos a escalabilidade em alta.
Para custos: Temos controles internos (e estamos construindo ativamente mais) para nos informar para onde nossos gastos estão indo. Ao nos concentrarmos nos itens mais caros um por um, mantemos os custos sob controle. Também definimos limites de taxa de chamadas e limites de tamanho para mitigar ataques de “Denial of Wallet”, minimizando as chances de incorrermos em custos enormes e imprevisíveis. Faremos mais, configurando alarmes que detectem anomalias no tráfego para que possamos investigar proativamente se eles são legítimos ou parte de ataques maliciosos.
Para minimizar a complexidade de depuração: Temos uma abordagem de três frentes: projetar adequadamente, documentar e manter a simplicidade. Embora algumas de nossas operações de API exijam o uso de eventos assíncronos para serem processadas em segundo plano (porque são muito longas para serem manipuladas durante uma solicitação da web de curta duração), as mantemos ao mínimo, colocamos em locais bem documentados no código e continuamente mantemos um controle sobre a complexidade adicional, fazendo com que engenheiros sêniores façam revisões de código de todas as mudanças que possam aumentar a complexidade.
E assim, temos a seguinte “stack” na Tenchi:
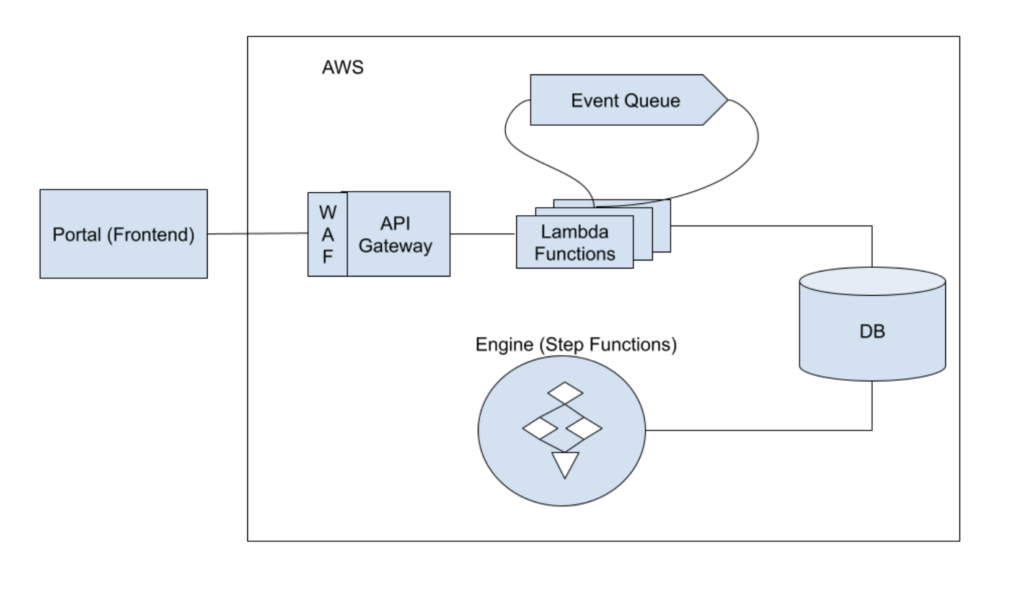
O front-end (nosso portal) é escrito no framework Angular, tudo em TypeScript.
Nossa API também é escrita em TypeScript sobre AWS WAF, Amazon API Gateway e funções Lambda, interagindo com sistemas AWS como EventBridge.
Finalmente, nosso “engine” é responsável por mais de quatro mil testes de segurança que o Zanshin executa diariamente em ambientes de nuvem e superfícies de ataque externas das empresas em nossa plataforma. Ele roda em cima do AWS Step Functions e é escrito principalmente em Python.
Então, aí está, nossa stack completa:
Frontend: Angular, em TypeScript.
API: API Gateway, Lambdas, EventBridge, em TypeScript.
Engine: Step Functions (Lambdas e trabalhos em lote) em Python.
Bancos de dados: DynamoDB e Aurora (Postgres).
Quatro anos depois, como essas escolhas se saíram? Bem, a escolha do TypeScript para o front-end e a API ainda faz muito sentido. Por um lado, as duas equipes trabalham juntas e é muito mais simples alternar o contexto entre a API e o Frontend quando se usa a mesma linguagem e ferramentas.
Em relação ao Angular em particular, essa é uma escolha que funcionou bem para nós. Ao mesmo tempo, o Angular parece estar perdendo seu apelo e popularidade. É um framework complexo e muito opinativo, o que significa que o pool de desenvolvedores por aí que se sentem confortáveis nesse ambiente está diminuindo. Ainda é cedo para descartar o Angular e ele nos serviu bem até agora, mas também estamos cientes de que se começássemos do zero hoje, provavelmente não usaríamos mais o Angular.
Quanto a “engine”, escolhemos o Step Functions devido à sua facilidade de configurar um sistema de fluxo com etapas, verificações e re-tentativas. Usamos Python porque a maioria das ferramentas de segurança e os SDKs para as APIs com as quais interagimos são escritos em Python. E por essa razão, a maioria dos especialistas em segurança, incluindo aqueles que atualmente trabalham na Tenchi, são bem versados em Python. Portanto, a escolha da linguagem foi boa. No entanto, isso cria uma situação em que compartilhar código entre a API e a “engine” é complicado. Para mitigar isso, temos uma API interna que torna o acoplamento entre a API e a “engine” independente.
Se estivéssemos começando do zero novamente, provavelmente escolheríamos uma linguagem única para todos os componentes do nosso sistema, para facilitar a mudança de contexto e o compartilhamento de código. Seria tentador escolher TypeScript novamente para que a equipe de front-end e a equipe de API pudessem se ajudar mutuamente com eficiência, como fazem agora, permitindo que a “engine” e a API compartilhem a lógica de negócios como bibliotecas.
No entanto, pensando nisso com mais atenção, nenhum código é compartilhado entre o front-end e a API e portanto, usar a mesma linguagem para elas não é um requisito forte. É um ponto especialmente fraco quando se considera que a maioria de nossos engenheiros pode alternar facilmente entre meia dúzia de linguagens.
A engine e a API, por outro lado, poderiam se beneficiar do uso da mesma linguagem, para que possam compartilhar bibliotecas comuns, mesmo que sejam executados em ambientes ligeiramente diferentes. Seria tentador escolher Python para ambos ou TypeScript para ambos. No entanto, eu argumentaria que o Node (o interpretador por trás do TypeScript) tem um custo inicial tão alto e uma grande pegada de memória que escolher algo mais eficiente como Go faria mais sentido. Economizaríamos dinheiro com o problema de Cold Start mencionado acima. Também tornaria nossos lambdas mais “finos” no quesito pegada de memória de acordo com um estudo recente feito por um de nossos engenheiros.
E para as ferramentas de segurança, sempre podemos usar Python em etapas específicas dentro do Step Functions, caso surja a necessidade. Além disso, espero que nossos engenheiros de segurança escrevam menos código no futuro, à medida que aumentamos nosso talento em engenharia de software.
No geral, a maioria das decisões tomadas há quatro anos foram boas e ainda se mantém hoje. Escolher uma arquitetura sem servidor foi definitivamente a decisão mais importante que tomamos. E mesmo as decisões menores que mudaríamos hoje, como a escolha da linguagem de programação e o framework de front-end, definitivamente não são fatais e, se muito, são apenas pequenos inconvenientes com os quais precisamos lidar.
– Eduardo Pinheiro, Diretor de Engenharia da Tenchi



